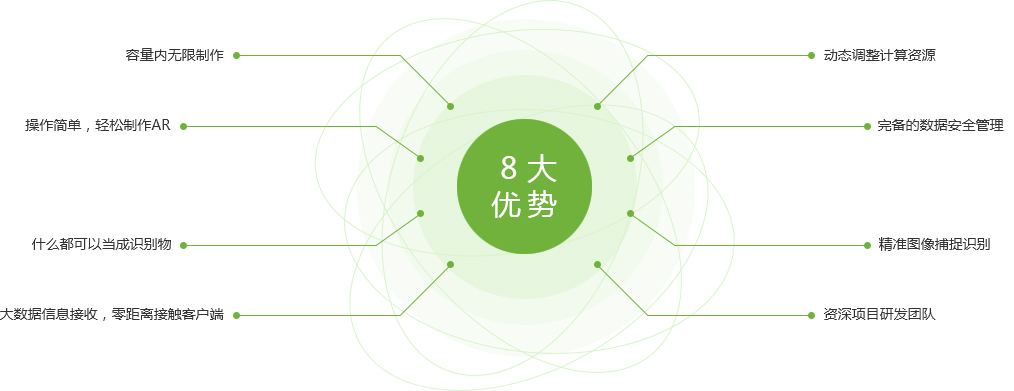
AR(Augmented Reality),即增强现实技术能将虚拟信息(图片,视频, 音频等)融入现实世界,让现实世界更加多元、丰富,为人们带来更加生动有 趣的感官体验。简单来说AR技术给人们带来的是一种信息的增强体验,它也 将成为一种“更新奇、更易传播”的新型信息传递方式。
在信息技术化的时代趋势下,AR将以一种新型娱乐及信息交互方式融入人们 的生活,而对于企业来说,AR产品的广泛推广及运用也将是一项不可错失的 绝佳商机。
中国AR网(公众号armeiti):很多人都喜欢玩honey select这个游戏,前面中国AR网也刚公布最新的honey select下载,相信大家都下载了,那么很多人会在我们的微博: chinaar平台反映,需要补丁以及出错,今天给大家公 ...
还在搜索适用于Android手机或iPhone的AR(增强现实)应用程序吗?这里给大家提供一个非常酷的列表,包括七款最好的AR(增强现实)应用程序。AR不只是一个科幻术语,而是实际存在于现实世界中的。毫无疑问,在手机上使用AR应 ...
三星显示公司(Samsung Display)认为,VR和AR可能成为促进移动OLED面板发展的技术。三星显示公司(Samsung Display)首席工程师Park Won-sang在首尔国际信息显示会议上表示,公司希望移动OLED市场能随着虚拟现实和增强现 ...